Dark energy force: fast deployment pipeline
microservice architecture architecting dark energy and dark matterContact me for information about consulting and training at your company.
The MEAP for Microservices Patterns 2nd edition is now available
a dark energy, dark matter force
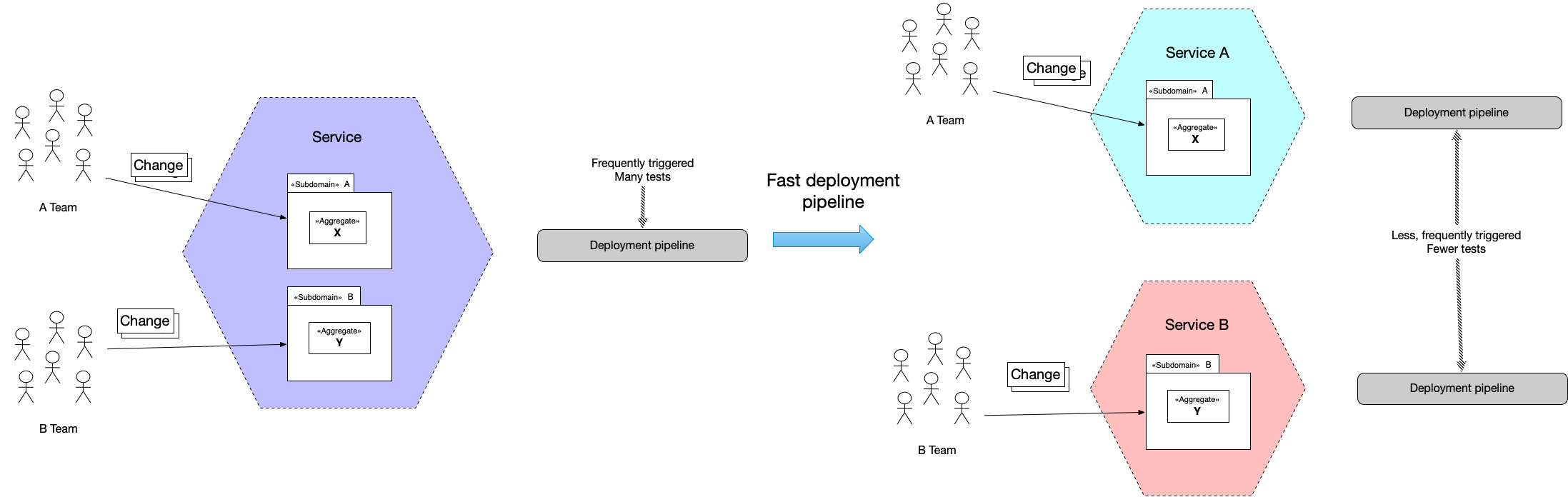
Rapid, frequent, and reliable software delivery needs a fast deployment pipeline. Let’s first look at why it’s needed. Then we’ll look at how to achieve it.
Why a fast deployment pipeline is important
DevOps/Continuous delivery needs a fast deployment pipeline. That’s because a key characteristic of continuous delivery is continuous integration. Developers commit their changes to trunk at least once a day, which are built and tested by a deployment pipeline. In addition, since developers must run pre-commit tests locally we can consider the first stage of the deployment pipeline to be the developer’s machines. In order to avoid being a bottleneck and provide fast feedback, the deployment pipeline must quickly build, test and deploy the change. Ideally, it should build, test and deploy a service within 15 minutes.
Moreover, developers should ideally be able to test locally on their own machines. Sometimes, however, local testing is not always possible. For example, a subdomain might require a separate test environment that can receive webhook requests from external services.
How to implement a fast deployment pipeline
There are four different ways to implement a fast deployment pipeline:
- Use build acceleration technologies
- Implement a merge queue
- Careful physical design of the component
- Design smaller components by separating subdomains
- Design components so they can be tested locally
Let’s look at each one in turn.
Use build acceleration technologies
The first way to accelerate the deployment pipeline is to use build acceleration technologies. There are three different technologies for accelerating builds:
- incremental builds - The build tool only rebuilds and tests only what has changed along with its transitive inbound dependencies.
- parallelized/distributed builds - the build tool concurrently builds and tests multiple modules using multiple cores, possibly on multiple machines.
For example,
gradlew --parallel ...will execute tasks belonging to different projects in concurrently. Bazel supports distributed builds that run on a cluster of machines. - build caching - build tools, such as Gradle and Bazel, can cache the results of a build task and reuse them when the task is run again.
Implement a merge queue
One challenge when many developers are frequently pushing changes to the same repository is that there can be a lot of contention. To push their changes, a developer must:
git pullto get the latest changes from trunk- run the pre-commit tests
git pushto push their changes to trunk
If there is a high volume of changes, there’s a good chance that the git push will fail because another developer has pushed their changes to trunk.
In this case, the developer start over, which is frustrating and time consuming.
A merge queue automates the process of merging changes to trunk. The developer creates a pull request, which is added to the queue. Build automation will build and test each queued pull request and merge it into trunk. Not only does the merge queue automate an otherwise tedious tasks, but it also ensures that the changes are tested before being merged into trunk.
Careful physical design of the component
The second way to accelerate the deployment pipeline is to design each subdomain so that its client subdomains depend on an abstract, and more stable interface rather than the concrete and less stable implementation. This approach is an application of the Dependency Inversion Principle. In addition, a client subdomain should be tested with a mock implementation of the subdomain. This design approach works in conjunction with incremental build technology to reduce the amount of code that needs to be rebuilt and tested when a subdomain is changed.
Design smaller components by separating subdomains
The third way to accelerate the deployment pipeline is to design smaller components. In other words, reduce the number of subdomains that are grouped together into a component and hence built and tested together. Instead of a large component that contains multiple subdomains, structure the application as a set of components each containing a single subdomain. Multiple teams can push changes concurrently and components will be built and tested concurrently.
Design components so they can be tested locally
The fourth way to accelerate the deployment pipeline is to design components so that they can be tested locally. That’s because local testing is much faster than having to deploy a component to a remote test environment. It also reduces the likelihood of a broken build since changes can be tested before being pushed to trunk.
The ability to test a components locally requires that its subdomains can be tested locally. If a subdomain requires a remote test environment then ideally it should be packaged as a separate component.