Chris Richardson 的微服务架构网站
本站由 Kong 提供支持微服务架构咨询和培训服务

本站点由 Chris Richardson 编写和维护,他是经典技术著作《POJOS IN ACTION》一书的作者,也是 cloudfoundry.com 最初的创始人。Chris 的研究领域包括 Spring、Scala、微服务架构设计、领域驱动设计、NoSQL 数据库、分布式数据管理、事件驱动的应用编程等。Chris 是一位连续创业者,eventuate.io 是他的最新创业项目,一个微服务应用和数据服务平台。
Chris 定期为企业提供微服务设计培训和实战项目的架构咨询服务。近年来 Chris 多次访问中国,为包括华为、SAP、惠普、东风汽车等大型企业提供微服务架构相关的技术咨询服务。如您希望与 Chris 深入交流,建立合作,请点击下方按钮跟他取得联系。
模式库
核心模式
服务拆分
部署模式
需要关注的边界问题
通讯模式
数据管理
安全模式
- 访问令牌new
可测试性
可观测性
UI 模式
- 服务器端页面碎片化元素构建new
- 客户端 UI 构建new
全新的微服务应用支撑平台,成功解决微服务架构下分布式数据管理的难题。
加入 微服务架构的 Google 讨论组(需要翻墙)
Pattern: Shared database
Context
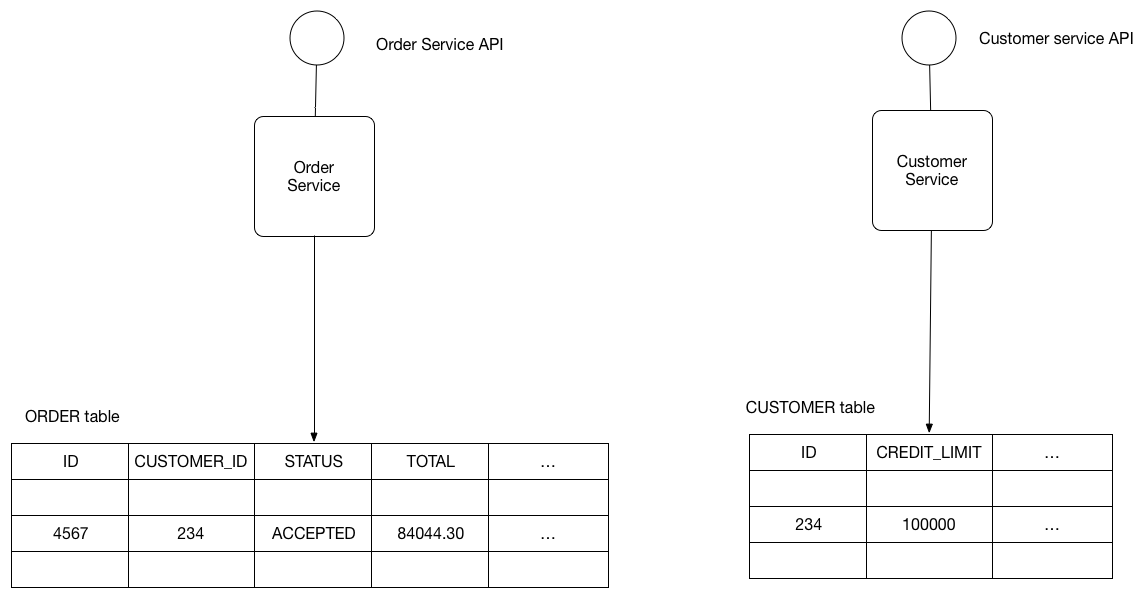
Let’s imagine you are developing an online store application using the Microservice architecture pattern.
Most services need to persist data in some kind of database.
For example, the Order Service stores information about orders and the Customer Service stores information about customers.
Problem
What’s the database architecture in a microservices application?
Forces
-
Services must be loosely coupled so that they can be developed, deployed and scaled independently
-
Some business transactions must enforce invariants that span multiple services. For example, the
Place Orderuse case must verify that a new Order will not exceed the customer’s credit limit. Other business transactions, must update data owned by multiple services. -
Some business transactions need to query data that is owned by multiple services. For example, the
View Available Credituse must query the Customer to find thecreditLimitand Orders to calculate the total amount of the open orders. -
Some queries must join data that is owned by multiple services. For example, finding customers in a particular region and their recent orders requires a join between customers and orders.
-
Databases must sometimes be replicated and sharded in order to scale. See the Scale Cube.
-
Different services have different data storage requirements. For some services, a relational database is the best choice. Other services might need a NoSQL database such as MongoDB, which is good at storing complex, unstructured data, or Neo4J, which is designed to efficiently store and query graph data.
Solution
Use a (single) database that is shared by multiple services. Each service freely accesses data owned by other services using local ACID transactions.
Example
The OrderService and CustomerService freely access each other’s tables.
For example, the OrderService can use the following ACID transaction ensure that a new order will not violate the customer’s credit limit.
BEGIN TRANSACTION
…
SELECT ORDER_TOTAL
FROM ORDERS WHERE CUSTOMER_ID = ?
…
SELECT CREDIT_LIMIT
FROM CUSTOMERS WHERE CUSTOMER_ID = ?
…
INSERT INTO ORDERS …
…
COMMIT TRANSACTION
The database will guarantee that the credit limit will not be exceeded even when simultaneous transactions attempt to create orders for the same customer.
Resulting context
The benefits of this pattern are:
- A developer uses familiar and straightforward ACID transactions to enforce data consistency
- A single database is simpler to operate
The drawbacks of this pattern are:
-
Development time coupling - a developer working on, for example, the
OrderServicewill need to coordinate schema changes with the developers of other services that access the same tables. This coupling and additional coordination will slow down development. -
Runtime coupling - because all services access the same database they can potentially interfere with one another. For example, if long running
CustomerServicetransaction holds a lock on theORDERtable then theOrderServicewill be blocked. -
Single database might not satisfy the data storage and access requirements of all services.
Related patterns
- Database per Service is an alternative approach