Microservice Architecture
Supported by KongThe Scale Cube
The book, The Art of Scalability, describes a really useful, three dimension scalability model: the scale cube.
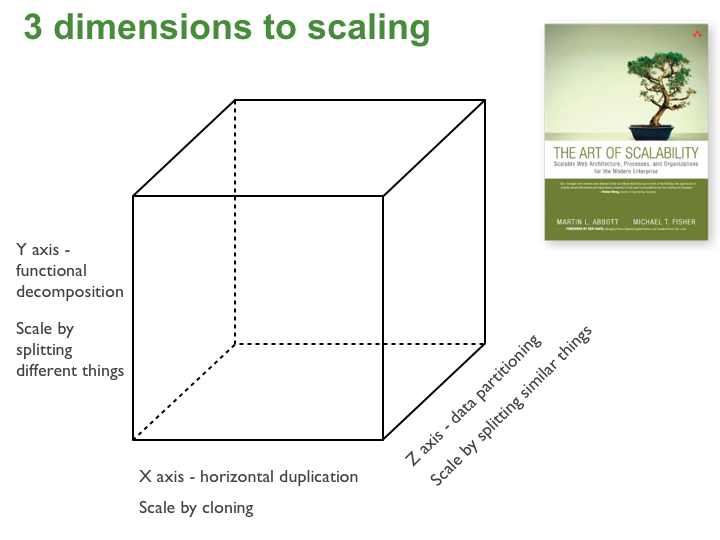
In this model, scaling an application by running clones behind a load balancer is known as X-axis scaling. The other two kinds of scaling are Y-axis scaling and Z-axis scaling. The microservice architecture is an application of Y-axis scaling but let’s also look at X-axis and Z-axis scaling.
X-axis scaling
X-axis scaling consists of running multiple copies of an application behind a load balancer. If there are N copies then each copy handles 1/N of the load. This is a simple, commonly used approach of scaling an application.
One drawback of this approach is that because each copy potentially accesses all of the data, caches require more memory to be effective. Another problem with this approach is that it does not tackle the problems of increasing development and application complexity.
Y-axis scaling
Unlike X-axis and Z-axis, which consist of running multiple, identical copies of the application, Y-axis axis scaling splits the application into multiple, different services. Each service is responsible for one or more closely related functions. There are a couple of different ways of decomposing the application into services. One approach is to use verb-based decomposition and define services that implement a single use case such as checkout. The other option is to decompose the application by noun and create services responsible for all operations related to a particular entity such as customer management. An application might use a combination of verb-based and noun-based decomposition.
Z-axis scaling
When using Z-axis scaling each server runs an identical copy of the code. In this respect, it’s similar to X-axis scaling. The big difference is that each server is responsible for only a subset of the data. Some component of the system is responsible for routing each request to the appropriate server. One commonly used routing criteria is an attribute of the request such as the primary key of the entity being accessed. Another common routing criteria is the customer type. For example, an application might provide paying customers with a higher SLA than free customers by routing their requests to a different set of servers with more capacity.
Z-axis splits are commonly used to scale databases. Data is partitioned (a.k.a. sharded) across a set of servers based on an attribute of each record. In this example, the primary key of the RESTAURANT table is used to partition the rows between two different database servers. Note that X-axis cloning might be applied to each partition by deploying one or more servers as replicas/slaves. Z-axis scaling can also be applied to applications. In this example, the search service consists of a number of partitions. A router sends each content item to the appropriate partition, where it is indexed and stored. A query aggregator sends each query to all of the partitions, and combines the results from each of them.
Z-axis scaling has a number of benefits.
- Each server only deals with a subset of the data.
- This improves cache utilization and reduces memory usage and I/O traffic.
- It also improves transaction scalability since requests are typically distributed across multiple servers.
- Also, Z-axis scaling improves fault isolation since a failure only makes part of the data in accessible.
Z-axis scaling has some drawbacks.
- One drawback is increased application complexity.
- We need to implement a partitioning scheme, which can be tricky especially if we ever need to repartition the data.
- Another drawback of Z-axis scaling is that doesn’t solve the problems of increasing development and application complexity. To solve those problems we need to apply Y-axis scaling.
About Microservices.io

Microservices.io is created by Chris Richardson, software architect, creator of the original CloudFoundry.com, and author of Microservices Patterns. Chris advises organizations on modernization, architecture, and building systems that avoid becoming modern legacy systems.
Need help modernizing your architecture?
Avoid the trap of creating a modern legacy system — a new architecture with the same old problems.
Contact me to discuss your modernization goals.
Microservices Patterns, 2nd edition

I am very excited to announce that the MEAP for the second edition of my book, Microservices Patterns is now available!
Learn moreASK CHRIS
Got a question about microservices?
Fill in this form. If I can, I'll write a blog post that answers your question.
NEED HELP?

I help organizations improve agility and competitiveness through better software architecture.
Learn more about my consulting engagements, and training workshops.


LEARN about microservices
Chris offers numerous other resources for learning the microservice architecture.
Get the book: Microservices Patterns
Read Chris Richardson's book:
Example microservices applications
Want to see an example? Check out Chris Richardson's example applications. See code
Virtual bootcamp: Distributed data patterns in a microservice architecture

My virtual bootcamp, distributed data patterns in a microservice architecture, is now open for enrollment!
It covers the key distributed data management patterns including Saga, API Composition, and CQRS.
It consists of video lectures, code labs, and a weekly ask-me-anything video conference repeated in multiple timezones.
The regular price is $395/person but use coupon OFFEFKCW to sign up for $95 (valid until Sept 30th, 2025). There are deeper discounts for buying multiple seats.
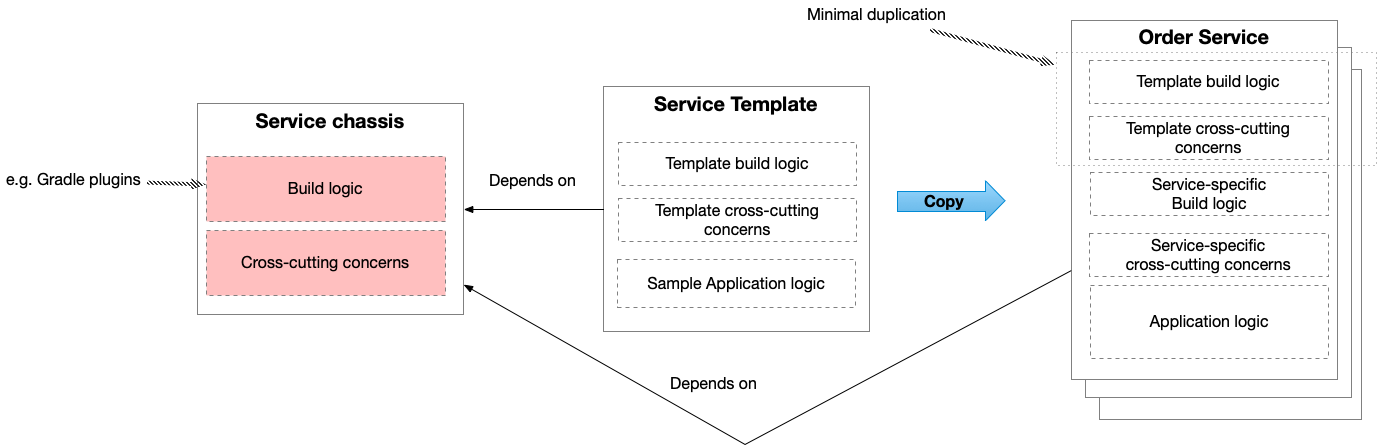
Learn how to create a service template and microservice chassis
Take a look at my Manning LiveProject that teaches you how to develop a service template and microservice chassis.
BUILD microservices
Consulting services
Engage Chris to create a microservices adoption roadmap and help you define your microservice architecture,
The Eventuate platform
Use the Eventuate.io platform to tackle distributed data management challenges in your microservices architecture.
Eventuate is Chris's latest startup. It makes it easy to use the Saga pattern to manage transactions and the CQRS pattern to implement queries.
Join the microservices google group
Topics
Note: tagging is work-in-process
Cynefin · DDD · GitOps · Microservices adoption · ancient lore · anti-patterns · api gateway · application api · application architecture · architecting · architecture · architecture documentation · assemblage · automation · beer · books · build vs buy · containers · context engineering · culture · dark energy and dark matter · decision making · deliberative design · deployability · deployment · deployment pipeline · design-time coupling · developer experience · development · devops · docker · eventuate platform · evolvability · fast flow · genAI development · generative AI · glossary · harness engineering · health · hexagonal architecture · idea to code · implementing commands · implementing queries · infrastructure as code · inter-service communication · kubernetes · loose coupling · manning publications · microservice · microservice architecture · microservice chassis · microservices adoption · microservices platforms · microservices rules · microservicesio updates · modifiability · modular monolith · multi-architecture docker images · observability · pattern · pattern language · patterns · platform strategy · refactoring · refactoring to microservices · resilience · runtime coupling · sagas · scripting · security · service api · service architecture · service blueprint · service collaboration · service design · service discovery · service granularity · service template · socio-technical architecture · software delivery metrics · success triangle · survey · tacos · team topologies · technical debt · testability · testing · transaction management · transactional messaging · wardley mapping
The patterns
Application architecture patterns
Decomposition
- Decompose by business capability
- Decompose by subdomain
- Self-contained Servicenew
- Service per teamnew
Refactoring to microservicesnew
Data management
- Database per Service
- Shared database
- Saga
- Command-side replica
- API Composition
- CQRS
- Domain event
- Event sourcing
Transactional messaging
Testing
Deployment patterns
- Multiple service instances per host
- Service instance per host
- Service instance per VM
- Service instance per Container
- Serverless deployment
- Service deployment platform
Cross cutting concerns
Communication style
External API
Service discovery
- Client-side discovery
- Server-side discovery
- Service registry
- Self registration
- 3rd party registration
Reliability
Security
Observability
- Log aggregation
- Application metrics
- Audit logging
- Distributed tracing
- Exception tracking
- Health check API
- Log deployments and changes
UI patterns