How modular can your monolith go? Part 2 - a first look at how subdomains collaborate
architecting modular monolithContact me for information about consulting and training at your company.
The MEAP for Microservices Patterns 2nd edition is now available
This article is the second in a series of articles about modular monoliths. The other articles are:
- Part 1 - the basics
- Part 3 - encapsulating a subdomain behind a facade
- Part 4 - physical design principles for faster builds
- Part 5 - decoupling domains with the Observer pattern
- Part 6 - transaction management for commands
- Part 7 - no such thing as a modular monolith?
In part 1 I described how a modular monolith is structured around the business domains rather than the technical concerns.
Some system operations (e.g. user requests) will be local to a single domain.
For example, createCustomer()
However, many system operations, especially the most complex ones and possibly the most important, will span multiple domains.
For example, as I described the end of the first article, createCustomer() needs to create a Customer and send out an email confirmation, which requires the customers and notifications domains to collaborate. Similarly, the createOrder() operation needs to create an Order, reserve credit in the Customer Service (which can fail) and send an order confirmation.
Since domains need to collaborate, we must consider domain API design and inter-domain collaboration mechanisms. What’s more, we need to think about the scope of (database) transactions. In this article, I focus on the first two issues, and assume that a system operation consists of a single transaction that spans subdomains. In a later post, I’ll discuss transaction management in more detail.
The monolithic customers and orders example
To provide more context, let’s start by looking at the monolithic customers and orders application in more detail. This application implements the following system operations:
createCustomer(name, creditLimit)- creates a customer with a credit limit and sends out a welcome emailcreateOrder(customerID, orderTotal)- creates anOrderfor the specified customer. It reserves credit for the order and sends out an order confirmation email.cancelOrder(orderID)- cancels the specifiedOrder, which releases the reserved credit.
The following diagram shows the application’s package structure:
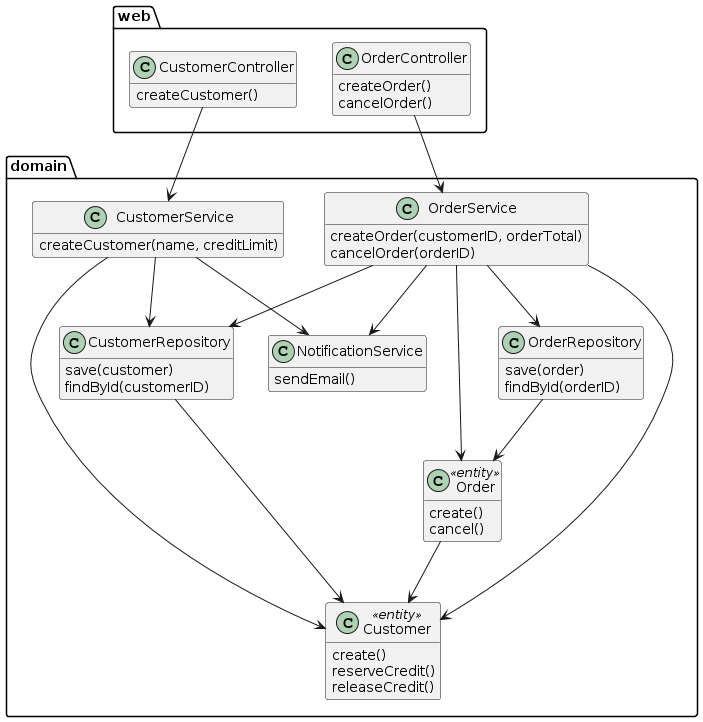
The Customer and Order entities are persisted using JPA.
Their repositories are implemented using Spring Data JPA.
There are two top-level packages: web and domain.
Each one is a separate Gradle sub-project.
Modularizing the monolith
Reorganizing the customers and orders application into a modular monolith results in a package structure that looks like this:
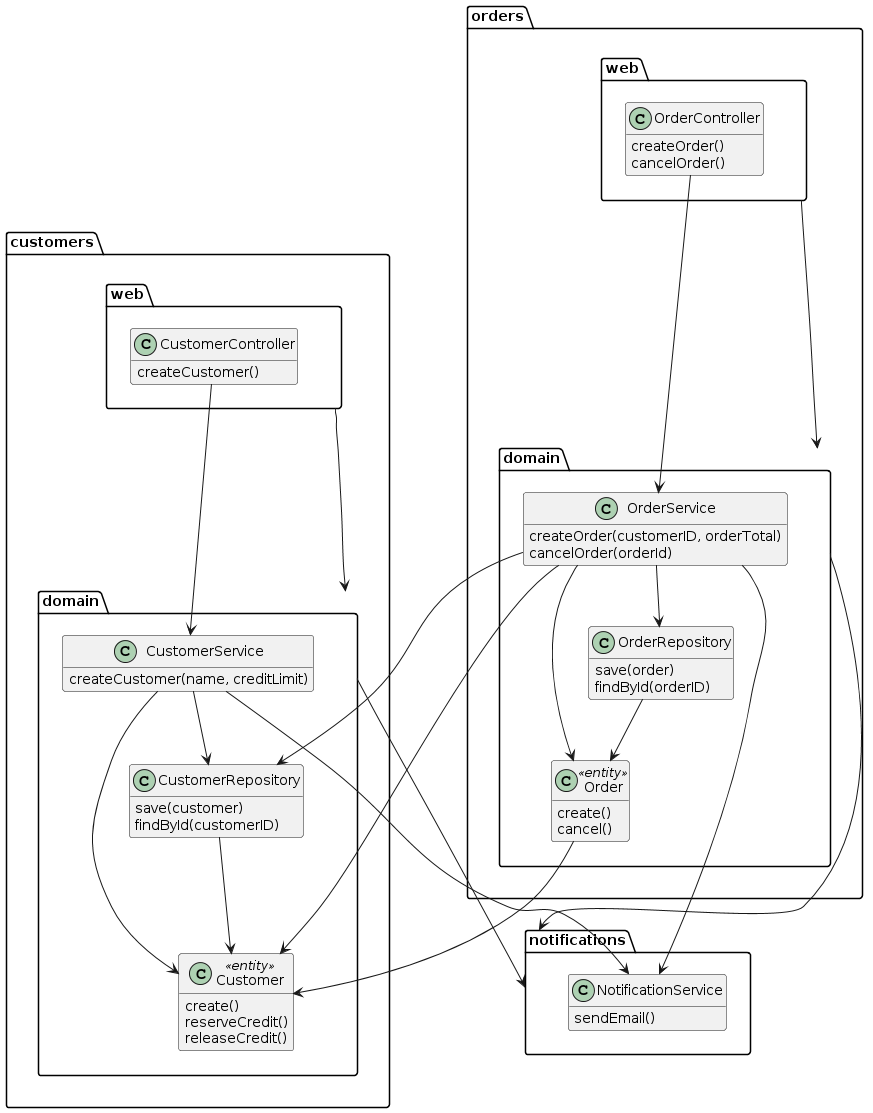
The top-level packages are customers, orders and notifications.
Each one contains the classes - controllers, services, and entities - for the corresponding domain.
Each top-level package is a separate Gradle sub-project.
About the inter-domain dependencies?
A notable feature of this design is that there are numerous inter-domain dependencies.
The CustomerService in the customers domain and the Order Service in the orders domain both invoke the NotificationService in the notifications domain.
The OrderService also invokes the CustomerRepository to retrieve the Customer entity.
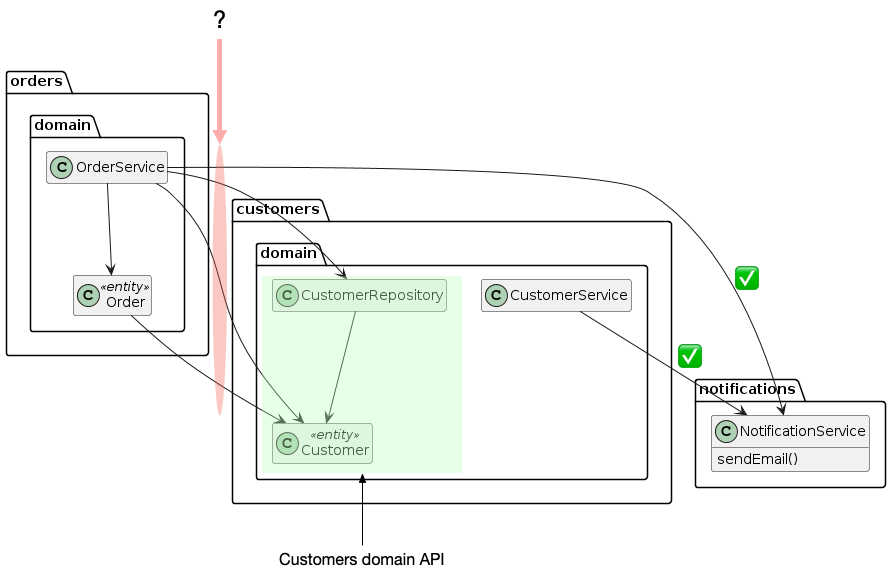
Furthermore, the Order entity has an @ManyToOne relationship with the Customer entity.
This reference associates the Order with the Customer.
It’s also used by the Order entity to release credit when it’s cancelled:
class Order ...
...
public void cancel() {
...
customer.releaseCredit(id);
this.state = OrderState.CANCELLED;
}
Behind the scenes, the ORM framework lazily loads the Customer, and when the transaction commits it executes SQL to update the underlying database tables.
This is an instance of a very common pattern in a rich domain model.
Not withstanding the endless and tedious debates about whether or not to use an ORM, this approach works well in many situations.
The dependency of the customers and orders domain on the NotificationService seems reasonable.
But the dependency of the orders domain on the CustomerRepository and Customer entity are highly suspicious.
Do these kinds of inter-domain reference make sense in modular monolith?
And more generally, how should these three subdomains collaborate?
As always, it depends.
In the remainder of this article, I’ll discuss one option - fine-grained subdomain APIs - and in a later articles, I’ll discuss other options.
Design option: subdomains with fine-grained APIs
One option is to allow fine-grained inter-domain references including inter-entity references that span subdomains.
Subdomain API = entities, repositories, etc.
In this example, the customers domain’s API consists of the Customer entity and the CustomerRepository.
In other words, it has a fine-grained API.
Let’s look at the benefits and drawbacks of this approach.
The benefits of a fine-grained API
This approach has some benefits:
- It’s a familiar programming model that supports a rich domain model that has OO-style relationships between entities.
- There’s no need for DTOs and the associated mapping code that other solutions typically require.
The drawbacks of a fine-grained API
Sadly, however, there are some significant drawbacks.
Lack of encapsulation
One key drawback is the lack of encapsulation and so there’s a risk of tight design-time coupling between the domains.
For example, the Customer entity is part of the customers domain’s API.
If the customers team wanted to replace the Customer entity with a Transaction Script, or, better yet, a quantum computing powered generative AI-based credit risk assessment algorithm, they’d have to coordinate with the orders team.
Such design-time coupling is a problem because it reduces team autonomy and slows down development.
Lack of testability
Another drawback of a fine-grained API is that it makes it difficult to test the domains in isolation.
Ideally, each domain should be testable in isolation using mocks for dependencies.
It simplifies the tests since there’s no need to initialize the dependencies.
Also, mocking often reduces the test execution time since the tests are simpler.
However, in this example, the customers domain’s fine-grained API is rather difficult to mock, which prevents its clients from being tested in isolation.
We could not, for example, test the orders domain without the customers domain, which complicates and slows down testing.
What about circular references?
Another issue is the existence of circular references between entities due to bidirectional associations.
For example, the Customer entity could have a one-to-many relation with the Order entity, in addition to the @ManyToOne Order-Customer relationship.
The problem with circular entity references in a modular monolith is that it creates a dependency cycle between the domains.
Such cycles are an obstacle to modularity since the domains need to be packaged in the same Maven module or Gradle sub-project.
Summary
While allowing subdomains to expose their entities and repositories is a simple approach, it has some significant drawbacks. In the next article, I’ll discuss an alternative approach that addresses these drawbacks by applying the Facade pattern.
Need help with your architecture?
I’m available. I provide consulting and workshops.