Handling duplicate messages using the Idempotent consumer pattern
Contact me for information about consulting and training at your company.
The MEAP for Microservices Patterns 2nd edition is now available
Let’s imagine that you developing a message handler for an enterprise application.
Unless the application is based entirely on streaming, it’s very likely that the message handler will need to update a database.
For example, in the Customers and Orders application, the Customer Service defines the OrderEventConsumer class event handler, which handles an OrderCreated event by attempting to reserve credit for the order.
Similarly, in the FTGO application, the Order History Service handles Order events by creating or updating the corresponding item in a DynamoDB-based CQRS view.
An application typically uses a message broker, such as Apache Kafka or RabbitMQ, that implements at-least once delivery. At-least once delivery ensures that messages will be delivered. It does mean, however, that the message broker can invoke a message handler repeatedly for the same message. You must use the Idempotent Consumer pattern to ensure that your message handlers correctly handle duplicate messages. In this post, I’ll describe why duplicate messages can occur and the problems they cause. You learn how to prevent those problems by making your message handlers idempotent. Let’s start by looking at why a message broker can deliver a message more than once.
Why can duplicate messages occur?
At a very high-level, a message handler executes the following pseudo code:
while (true) {
Read message
Begin database transaction
… update one or more business objects…
Commit database transaction
Acknowledge message
}
A message handler loops repeatedly executing the following three steps. First, it reads a message from the message broker. Second, the message handler updates the database, Finally, it acknowledges the message, which tells the message broker that it has been processed successfully and should not be redelivered.
It’s possible, however, that the message handler successfully updates the database but somehow fails to acknowledge the message. The message handler might crash, for example. Alternatively, the broker might crash and lose the acknowledgement. A message broker that guarantees at-least once deliver recovers from these kinds of failures by repeatedly delivering the message until it has been successfully processed. As a result, a message handler can execute the database transaction multiple times for the same message.
If you are using a message broker, such as Apache Kafka, that offers a form of exactly once semantics, you might think that your application won’t encounter duplicate messages. But if you read the fine print, you will discover that the guarantee only applies to Apache Kafka messaging. Specifically, if Apache Kafka invokes a message handler more than once for the same message, it detects and discards any duplicate messages produced by the handler. The message handler will still execute the database transaction repeatedly.
Idempotency is important
A message handler must be idempotent: the outcome of processing the same message repeatedly must be the same as processing the message once. Some message handlers are inherently idempotent but others need to be made idempotent. Whether or not a message handler is naturally idempotent depends on the details of the business logic.
Consider, for example, a message handler for AccountDebited events that updates the account’s current balance in a CQRS view.
On the one hand, if the AccountDebited event has a currentBalance attribute then the handler simply updates the view with that new value.
This message handler is naturally idempotent and can be safely process the same event multiple times.
But on the other hand, let’s imagine that the AccountDebited event contains only the debit amount.
The message handler must update the current balance by subtracting the debit amount.
This message handle is not idempotent because if it processed the same message repeatedly then the current balance would be incorrect.
To prevent this bug, the application must use a mechanism to make the message handler idempotent.
Tracking message IDs
You can make a message handler idempotent by recording in the database the IDs of the messages that it has processed successfully.
When processing a message, a message handler can detect and discard duplicates by querying the database.
There are a couple of different places to store the message IDs.
One option is for the message handler to use a separate PROCESSED_MESSAGES table.
The other option is for the message handler to store the IDs in the business entities that it creates or updates.
Let’s first look at how to use a PROCESSED_MESSAGES table.
Save messages in a PROCESSED_MESSAGE table
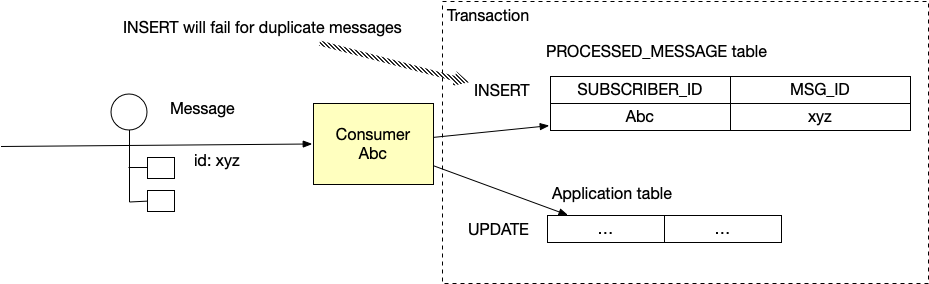
One straightforward solution is to track the message IDs that have been processed in a separate table Here is the pseudo code that implements this algorithm.
while (true) {
Read message
Begin database transaction
INSERT into PROCESSED_MESSAGE (subscriberId, ID) VALUES(subscriberId, message.ID)
… update one or more business objects…
Commit transaction
Acknowledge message
}
After starting the database transaction, the message handler inserts the message’s ID into the PROCESSED_MESSAGE table.
Since the (subscriberId, messageID) is the PROCESSED_MESSAGE table’s primary key the INSERT will fail if the message has been already processed successfully.
The message handler can then abort the transaction and acknowledge the message.
Eventuate Tram’s SqlTableBasedDuplicateMessageDetector implements this behavior.
You can enable SqlTableBasedDuplicateMessageDetector in your application by adding a dependency on eventuate-tram-spring-consumer-jdbc and then using either @EnableAutoConfiguration or @Import(TramConsumerJdbcAutoConfiguration.class).
Tracking IDs in a PROCESSED_MESSAGE table is conceptually straightforward.
But it relies on the database supporting transactions that span multiple tables.
That’s not a problem when using SQL database but it’s not always suitable when using a NoSQL database.
Let’s look at an alternative approach that does not require multi-table database transactions.
Store message IDs in the business entities created or updated by message handlers
Instead of storing the IDs in a separate table, a message handler can store them in the entities that it creates and updates. A message handler that works this way typically creates or updates an entity and performs a duplicate check using a single database operation. Since this approach doesn’t rely on general purpose transactions, it’s particularly useful when developing message handlers that use a NoSQL database.
For example, the FTGO application’s Order History Service implements a DynamoDB-based CQRS view.
The view consists of the ftgo-order-history table, which contains an an item for each order.
It’s kept up to date by event handlers for Order and Delivery events.
One way to make these message handlers idempotent is for each Order table item to have a set valued messageIDs attribute.
This attribute stores the IDs of the messages that have triggered the creation or the update of the table item.
A message handler creates or update an Order using a DynamoDB update operation that adds the message’s ID to the messageIDs attribute.
The update is made idempotent by using a conditional expression that verifies that the messageIDs attribute doesn’t already contain the ID.
The Order History Service service uses a variation of this approach that exploits the fact that event IDs published by an aggregate instance increase monotonically.
Rather than storing all IDs, a message handler can simply store the highest event ID published by each aggregate instance.
An Order item has one or more attributes named events.<<aggregateType>>.<<aggregateId>> whose value is the highest event ID seen so far from each aggregate instance.
An update operation uses a conditional expression that verifies that either this attribute does not exist or that its value is less than current event’s ID.
This way of tracking message IDs works especially well for the Order History Service service since only a small number of aggregates publish events that trigger the creation and updating of a given Order table item.
Summary
A message broker can deliver the same message repeatedly.
To prevent duplicate messages from causing bugs, a message handlers must use the Idempotent Consumer pattern.
If a message handler is not inherently idempotent, it must record successfully processed messages and discard duplicates.
A message handler can store IDs in either a PROCESSED_MESSAGES table or in the business entities that it creates or updates.
Learn
To learn more about how to develop message-based microservices:
- Read my book Microservices patterns
- Check out my open-source Eventuate Tram framework