Introducing Assemblage - a microservice architecture definition process
application architecture architecting dark energy and dark matter assemblageContact me for information about consulting and training at your company.
The MEAP for Microservices Patterns 2nd edition is now available
The essence of applying the Microservice architecture pattern is defining the service architecture: identifying the services, defining their responsibilities, their APIs and their collaborations (with other services). Choosing the right technical architecture - deployment platform, message broker, etc. - also matters. But that’s a far easier and much less important task. That’s because if you define your services incorrectly you will create a fragile, and difficult to maintain distributed monolith that can threaten your organization’s very existence. And to make matters worse, defining the service architecture isn’t just a matter of reading the manual. It’s a design activity that involves numerous, and often tricky trade-offs.
I’ve written a lot about how the dark energy and dark matter forces can help define a service architecture. And, in a few talks, I’ve briefly described the architecture definition process, which is based on dark energy/matter, that I like to use. But until now, it’s not something I’ve described in detail outside of my microservice architecture workshops. The goal of this article is to properly introduce my architecture definition process, which I’ve named Assemblage.
Overview of Assemblage
The input to the architecture definition process consists of the application’s requirements, e.g. user stories/scenarios, non-functional requirements, wireframes, etc. The output of the process is a service architecture, which consists of the services, and their responsibilities, APIs, and collaborations.
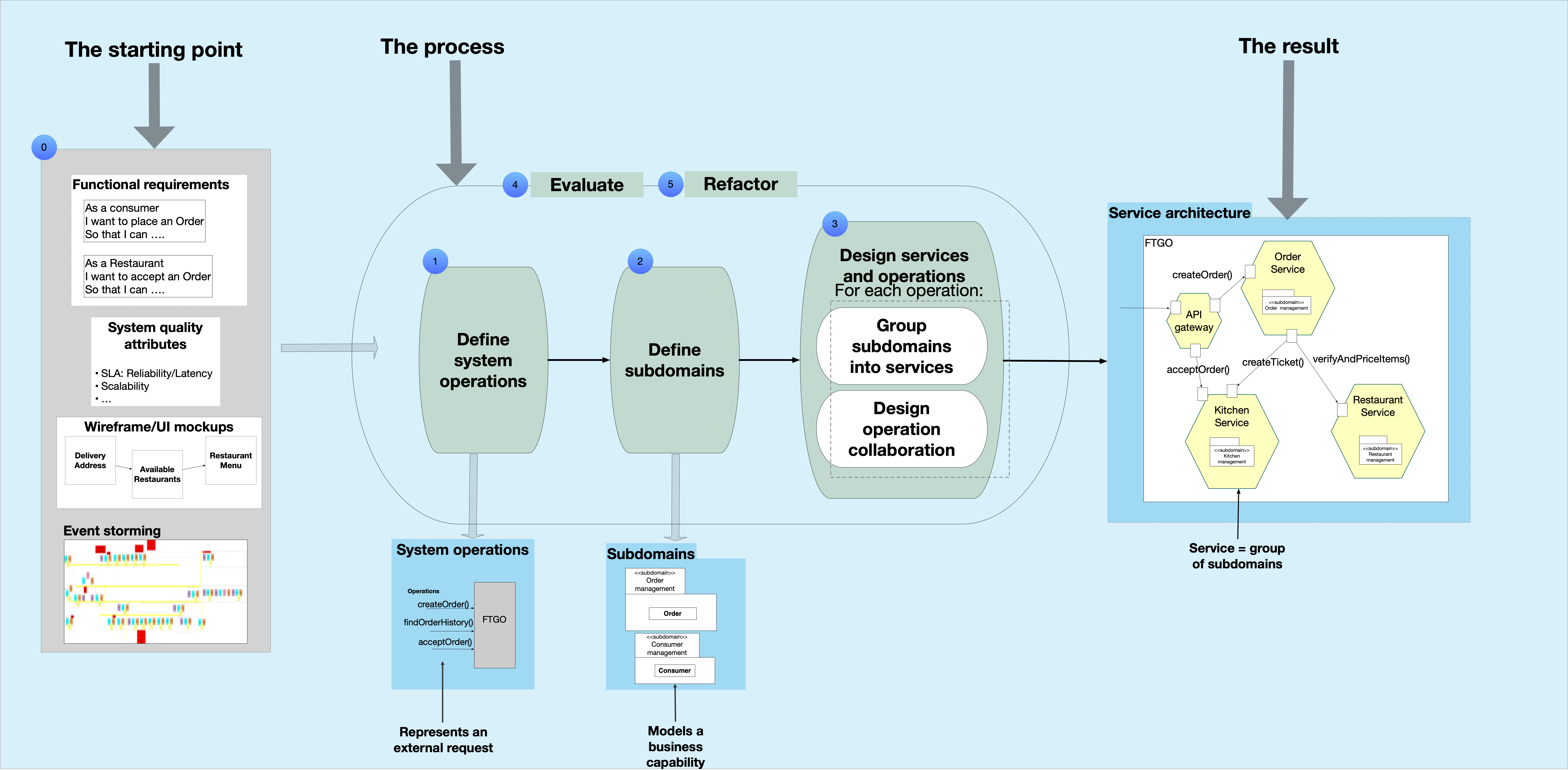
The architecture definition process consists of the following steps:
- Discovering system operations
- Defining subdomains
- Designing services and their collaborations
- Evaluating a microservice architecture
- Refactoring a microservice architecture
Step 1: Discovering system operations
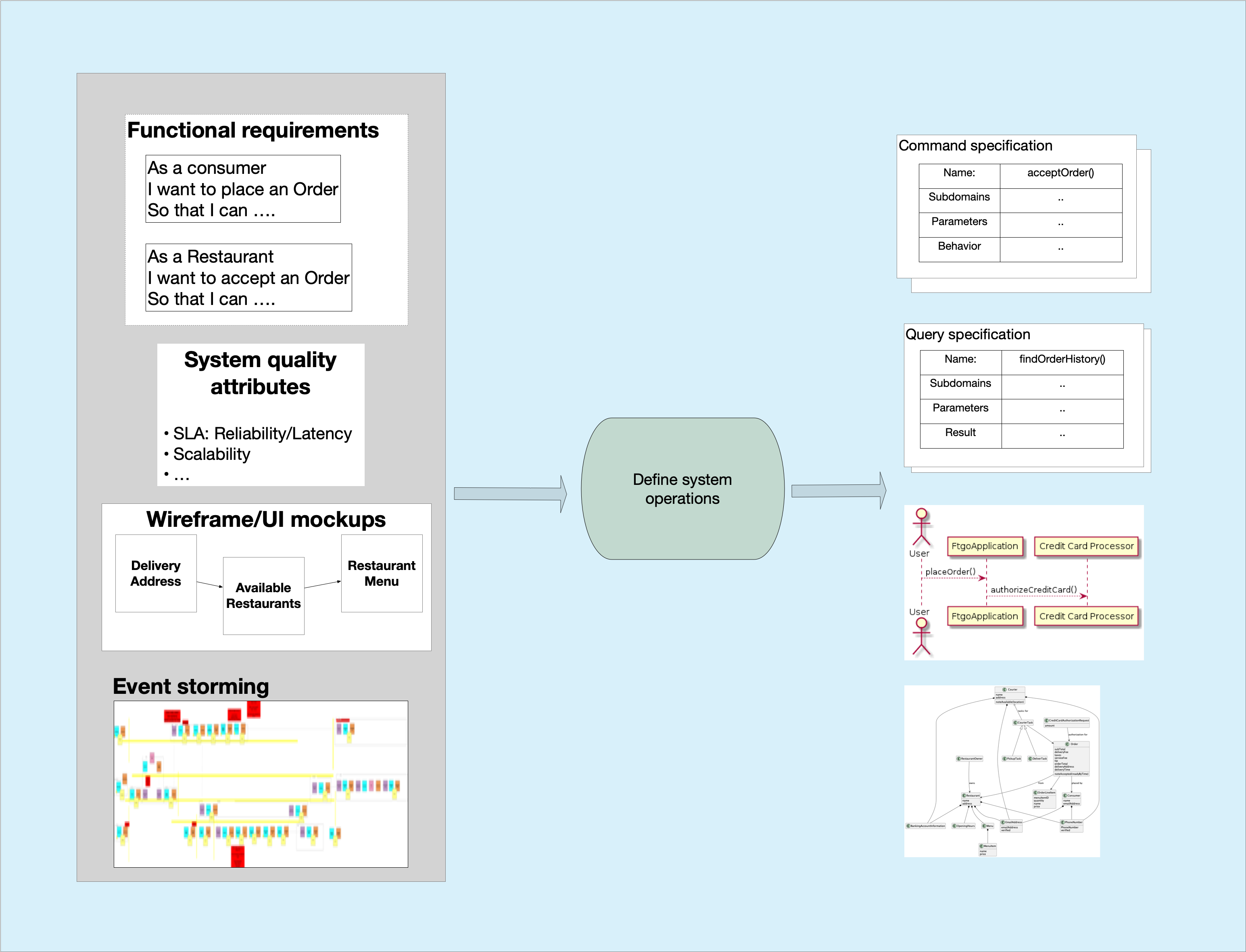
The first step of the process distills the requirements into a set of system operations.
A system operation is an invokable behavior implemented by the application.
For example, an e-commerce application would typically implement operations such as createCustomer(), createOrder(), cancelOrder() and findOrderHistory().
A system operation reads and/or writes one or more business entities, a.k.a. DDD aggregates, such as Customer and Order.
The system operations model the application’s black box behavior.
A system operation is technology independent. But the actual implementation will be invoked in one of several ways. It might, for example, be invoked by a HTTP request or a message. Alternatively, a system operation might be triggered by the passing of time, eg. a monthly batch job.
Step 2: Defining subdomains
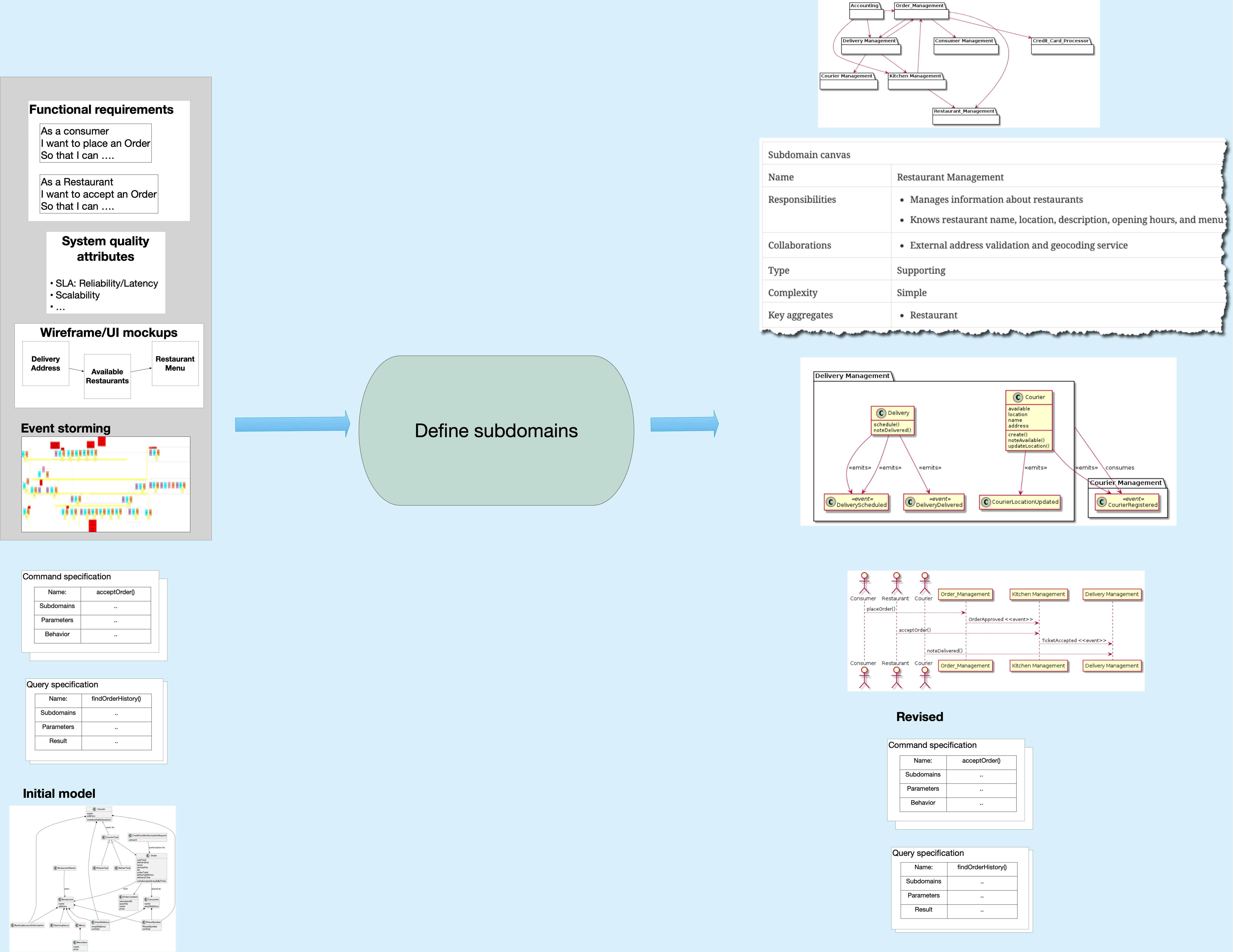
The second step of the process defines the subdomains. A subdomain is an implementable model of a sliver of business functionality, a.k.a. business capability. Each subdomain is owned by a small team. A subdomain consists of the aggregates acted upon by system operations. In Java application, for example, a subdomain would consist of Java classes.
Step 3: Designing services and their collaborations
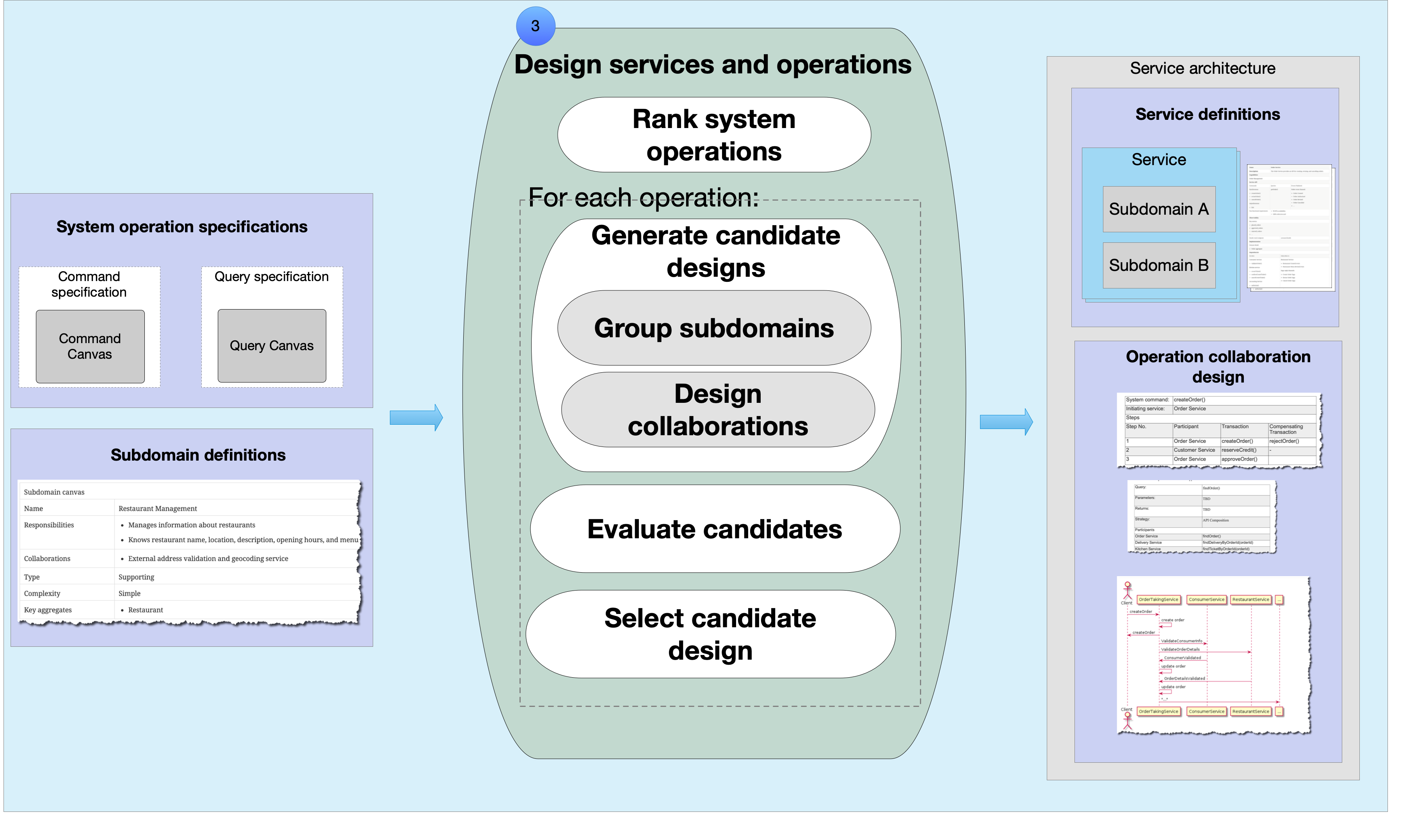
The third step defines the service architecture by grouping the subdomains to form services and designing distributed system operations using the service collaboration (e.g. Saga, API Composition, and CQRS) patterns.
The dark energy and dark matter forces drive the definition of services and the design of system operations.
The output of the third step is a candidate service architecture that is either a monolithic architecture (i.e. a single service) or a microservice architecture (two or more services). The architecture documentation includes a microservice canvas for each service.
Step 4: Evaluating the microservice architecture
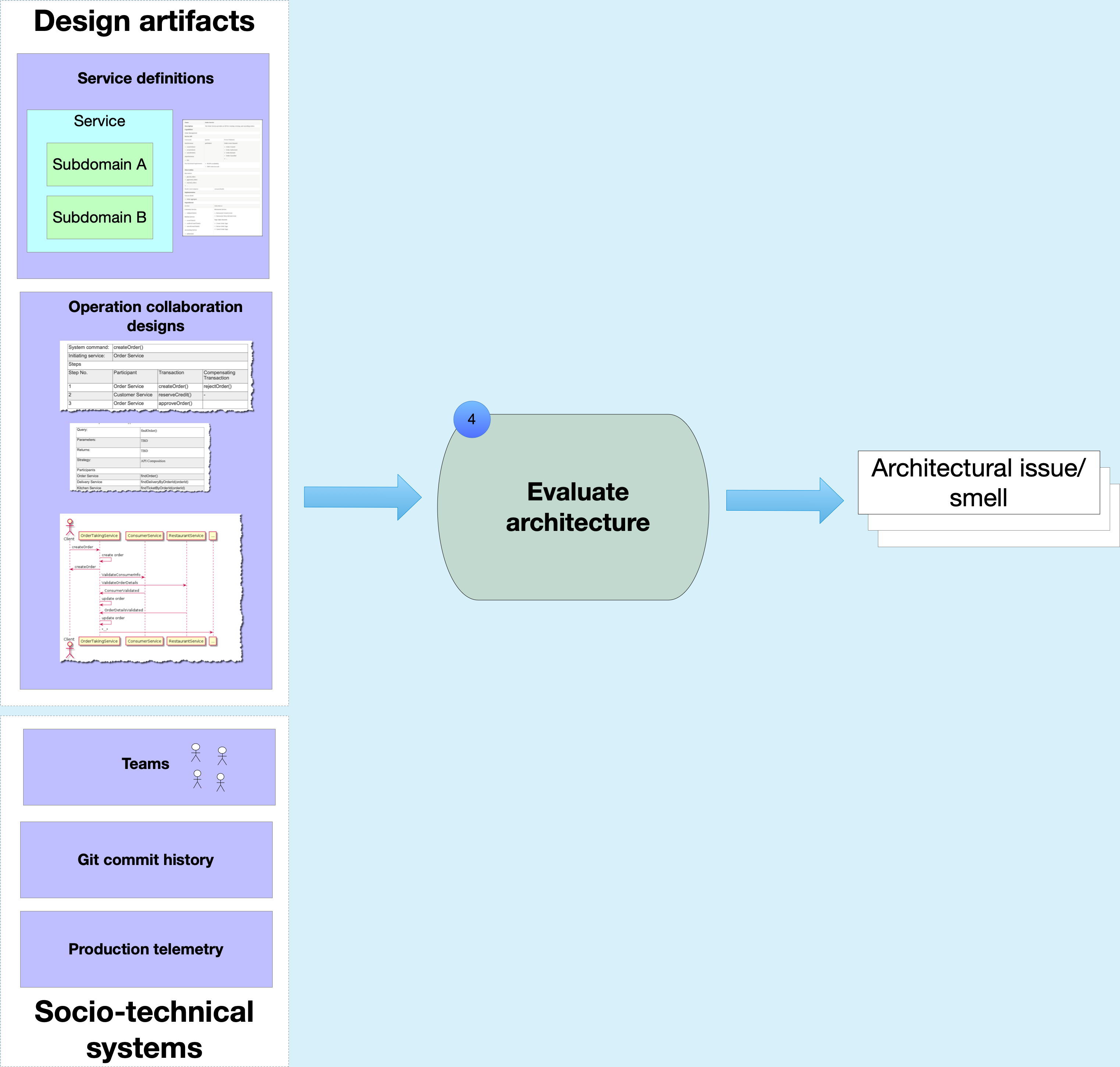
The fourth step evaluates the architecture to identify architectural issues/smells that are potential violations of the dark energy and dark matter forces.
Examples of architectural issues/smells include
- Teams that lack of autonomy because too many teams work together on the same service
- Services that repeatedly change in lockstep due to design time coupling
- Operation that have low availability and high latency because they span too many service and require too many network round trips
The output of fourth step is a list of potential architectural issues.
Step 5: Refactoring the microservice architecture
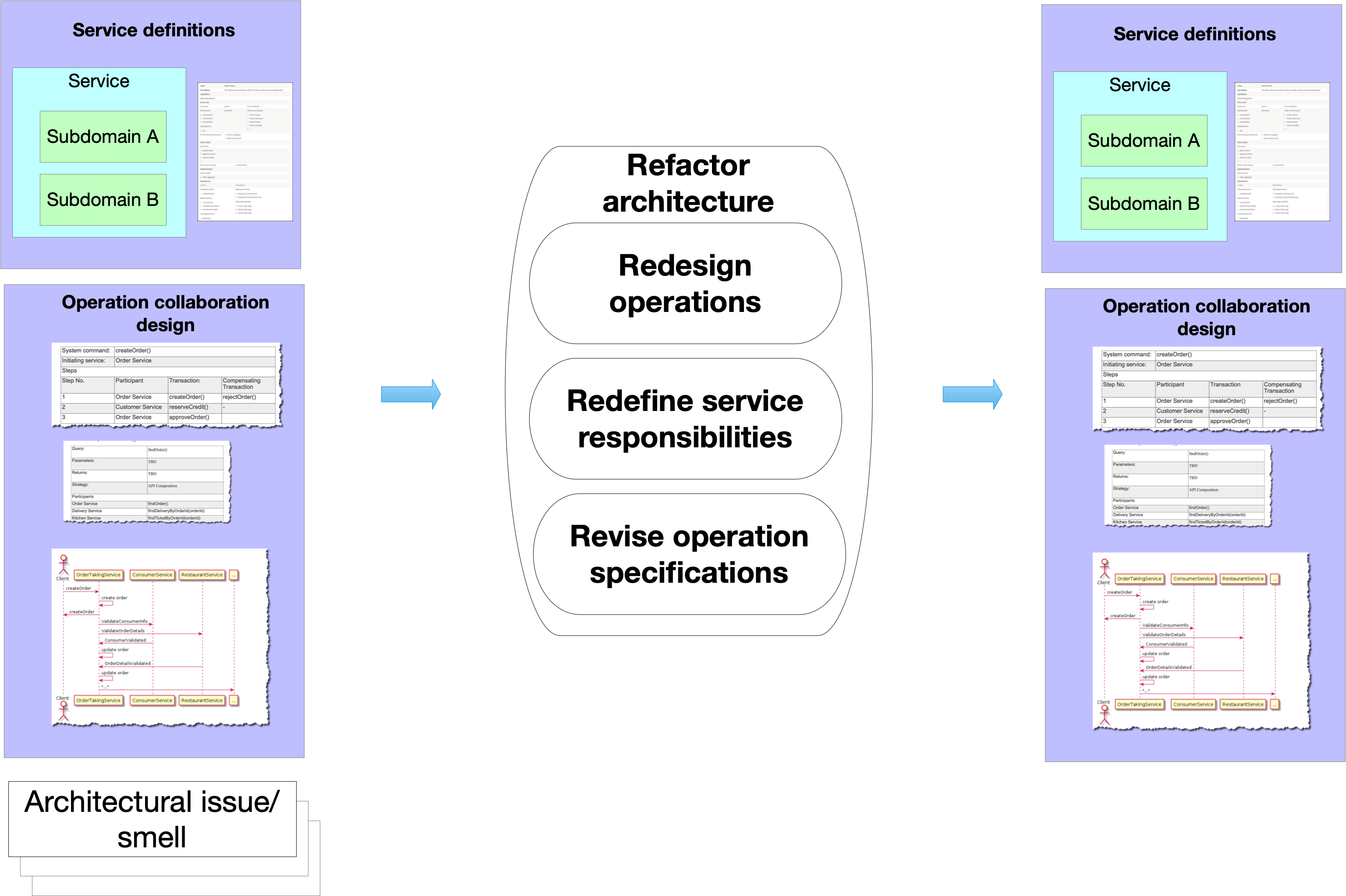
The fifth and final step refactors the architecture to eliminate architecture smells identified in the previous step. There are four levels of refactorings:
- System operations - e.g. change collaboration patterns
- Services - eg. move subdomains between services
- Subdomains - e.g. split subdomains
- System operation specifications - e.g. to reduce runtime coupling
The output of the fifth step is an improved microservice architecture.
When to use this process
- Defining a target architecture (e.g. monolithic or microservices) for greenfield development
- Defining a target microservice architecture when refactoring a monolith to microservices
- Implementing new or changing requirements
- As part of an on-going architectural governance process that ensures that the architecture continues to satisfy its non-functional requirements
Where to go from here
This process defines the services, and their responsibilities, APIs, and collaborations. The next step is to define the technical architecture. A big part of defining the technical architecture is selecting and applying the application infrastructure and infrastructure patterns from the microservices pattern language, e.g. deployment, observability, inter-service communication, etc. That’s a topic that I will describe in detail in future articles.
Learn more in my workshop
I’m available to teach a designing a microservice architecture definition workshop to teams at your organization. Please don’t hesitate to contact me.
Please note this workshop is only available for teams, not individuals.
Want to teach Assemblage to others?
If you want to teach Assemblage to your clients or to others in your enterprise, please contact me to discuss licensing options.