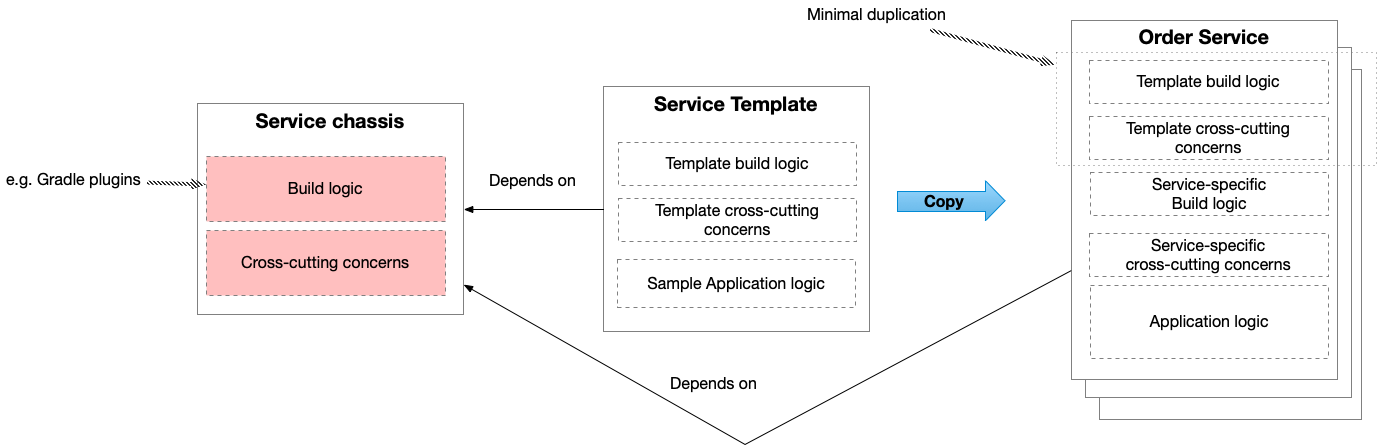
Extracting the Delivery Service - Step 3: define standalone Delivery Service
The previous post described the second step of the refactoring process, which consisted of splitting the ftgo database schema and defining an ftgo_delivery_service schema.
The third step of the refactoring process is to define a standalone Delivery Service and deploy it.
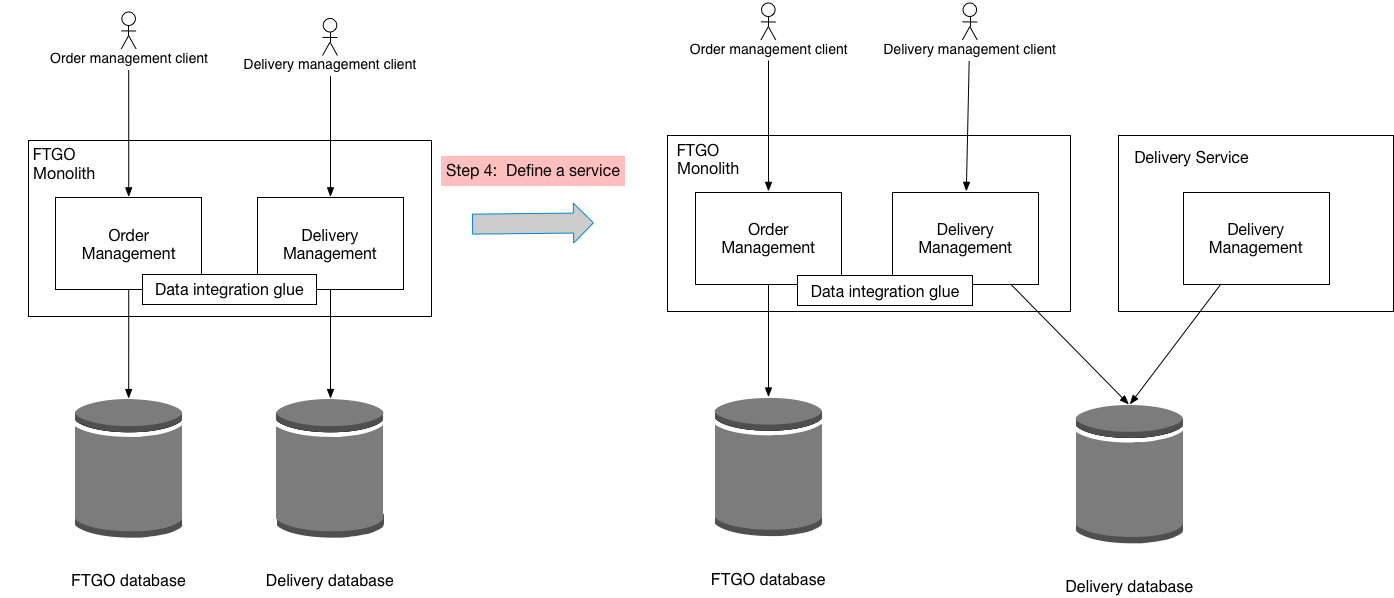
The following diagram shows the design:
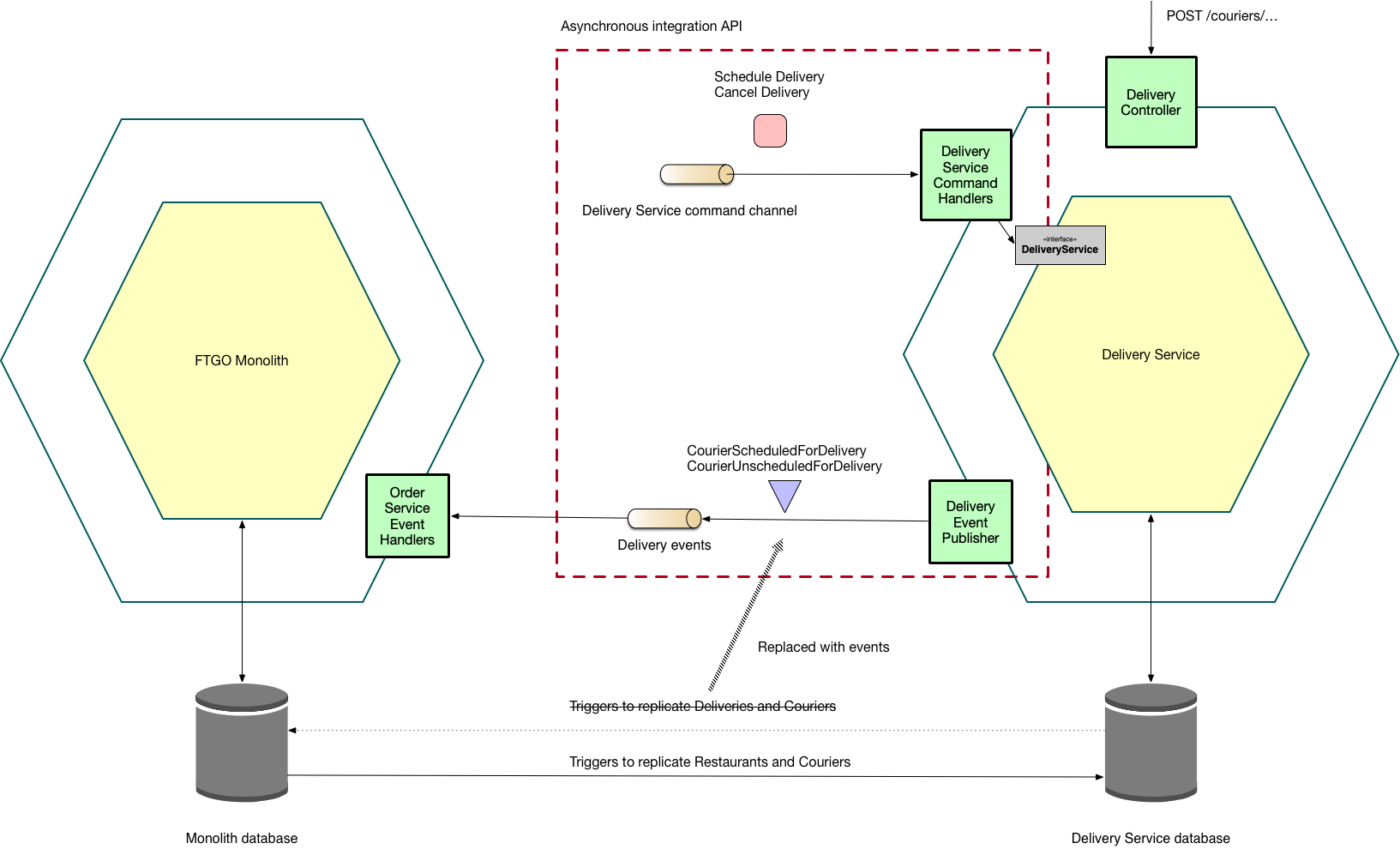
The Delivery Service’s API consists of:
- A REST API, which is implemented by the
DeliveryController - A request/asynchronous response-style API, which is implemented by
DeliveryServiceCommandHandlers, that will eventuallybe used by the FTGO monolith for scheduling and cancelling deliveries - An event publishing API, which is implemented by
DeliveryEventPublisher, that publishes events when a courier’s schedule has been updated. It’s used instead of database triggers to replicate updates to courier’s schedules to the monolith. TheFTGO monolithnow contains aOrderServiceEventHandlers, which subscribes to the events published byDelivery Managementand updates its local data.
Module structure
The following diagram shows the new module structure:
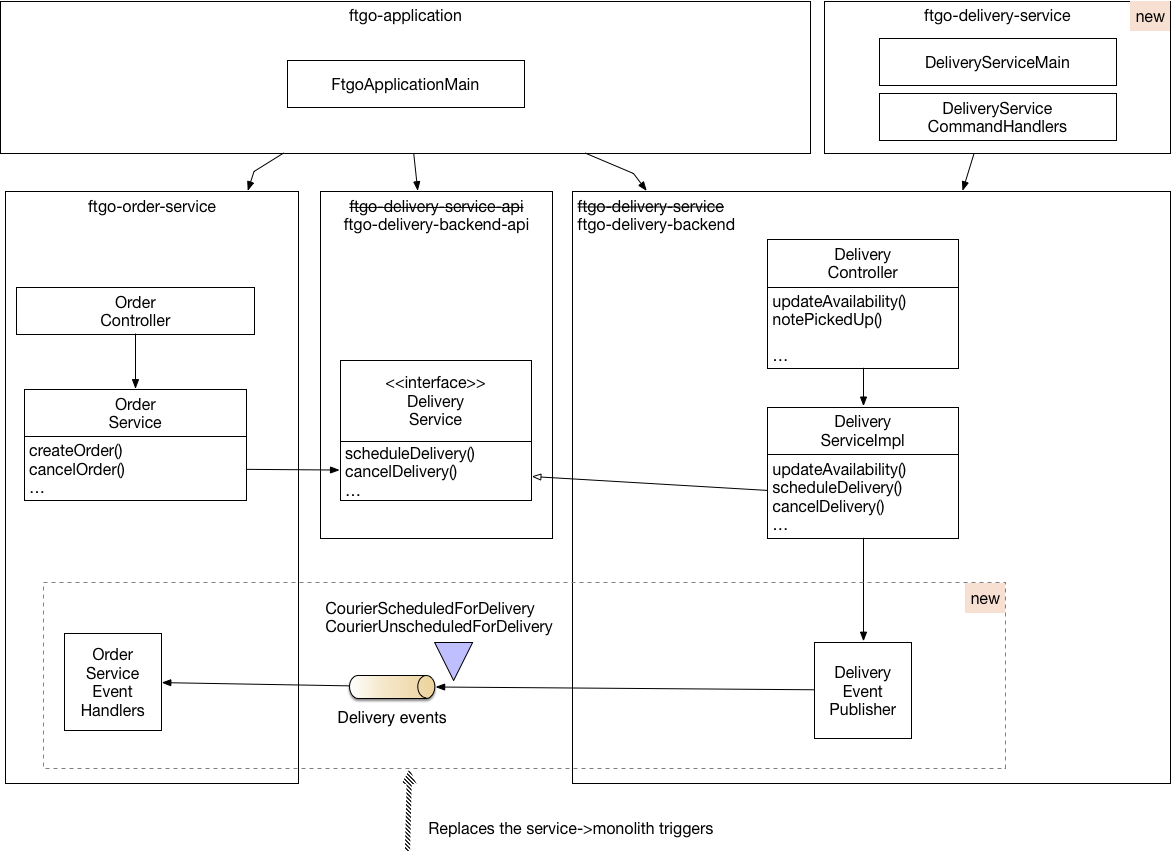
There are the following modules:
ftgo-delivery-backend*- previously these were theftgo-delivery-service*modulesftgo-delivery-service- a new module, which contains theDelivery Service’s main class and theDeliveryServiceCommandHandlers. It reuses theftgo-delivery-backendmodule from the monolith rather than implementing the delivery management logic from scratch.
The event-based data integration glue is implemented by classes in the following modules:
ftgo-delivery-backend- contains theDeliveryEventPublisherclass.ftgo-order-service- contains theOrderServiceEventHandlersclass.
Since these modules are part of the FTGO monolith, it uses the same event-based mechanism internally.
Why replace triggers with events?
One benefit of using triggers to synchronize two databases is that it doesn’t require any changes to the code. The synchronization is handled entirely by the database. A significant drawback, however, of using triggers is that it results in tight design-time and runtime coupling between the two databases. There is design-time coupling between the database, because a trigger has knowledge of both databases. There is also runtime coupling since both databases are updated within a single transaction.
Another drawback of using triggers is that the coupling makes it difficult to test the newly extracted service in isolation.
Consider, for example, a test that verifies that the Delivery Service correctly processes a ScheduleDelivery command message.
If a trigger replicates updates to a Courier’s schedule from ftgo_delivery_service database to the ftgo database then the test must correctly setup that database as well.
A much better approach is to use events to replicate changes.
The Delivery Service can, for example, publish domain events when it updates a Courier’s schedule.
The FTGO application subscribes to those events and updates its database.
An event-based replication mechanism has the following benefits:
- Reduced design-time coupling - services communicate via APIs rather than access each other’s implementation details
- Eliminates runtime coupling - there is no longer runtime coupling between the services
- Improved testability - a test can easily verify that a service emits the expected events
It also has a couple of drawbacks. The first drawback of using events is that you need to change the application code to publish and consume events. In particular, modifying all of the places that publish events in a monolithic application might be prohibitively time consuming and error-prone.
The second drawback of using events to replicate changes is that it is eventually consistent.
Unlike triggers, which execute within the ACID transaction that updates the source database, an event handler runs in a separate database transaction
For example, the FTGO application executes the acceptOrder() command in a single transaction, which accepts the Order in the ftgo database, schedules the Delivery in the ftgo_delivery_service database, and replicates the changes (via a trigger) back to the ftgo database.
In contrast, the event-based design uses two transactions.
The first transaction accepts the Order in the ftgo database, and schedules the Delivery in the ftgo_delivery_service database.
The second transaction replicates the changes back to the ftgo database.
As a result, the acceptOrder() command no longer updates the Courier’s schedule.
In the future, the FTGO application might use events.
But for now, we’ll just change Delivery Management to publish events it’s a relatively small change that makes it much easier to test the Delivery Service.
About DeliveryServiceComponentTest
Because the Delivery Service uses events rather than triggers to replicate changes to the FTGO application it’s straightforward to test the service in isolation.
DeliveryServiceComponentTest implements a component test for the Delivery Service.
The following diagram shows how this test works:
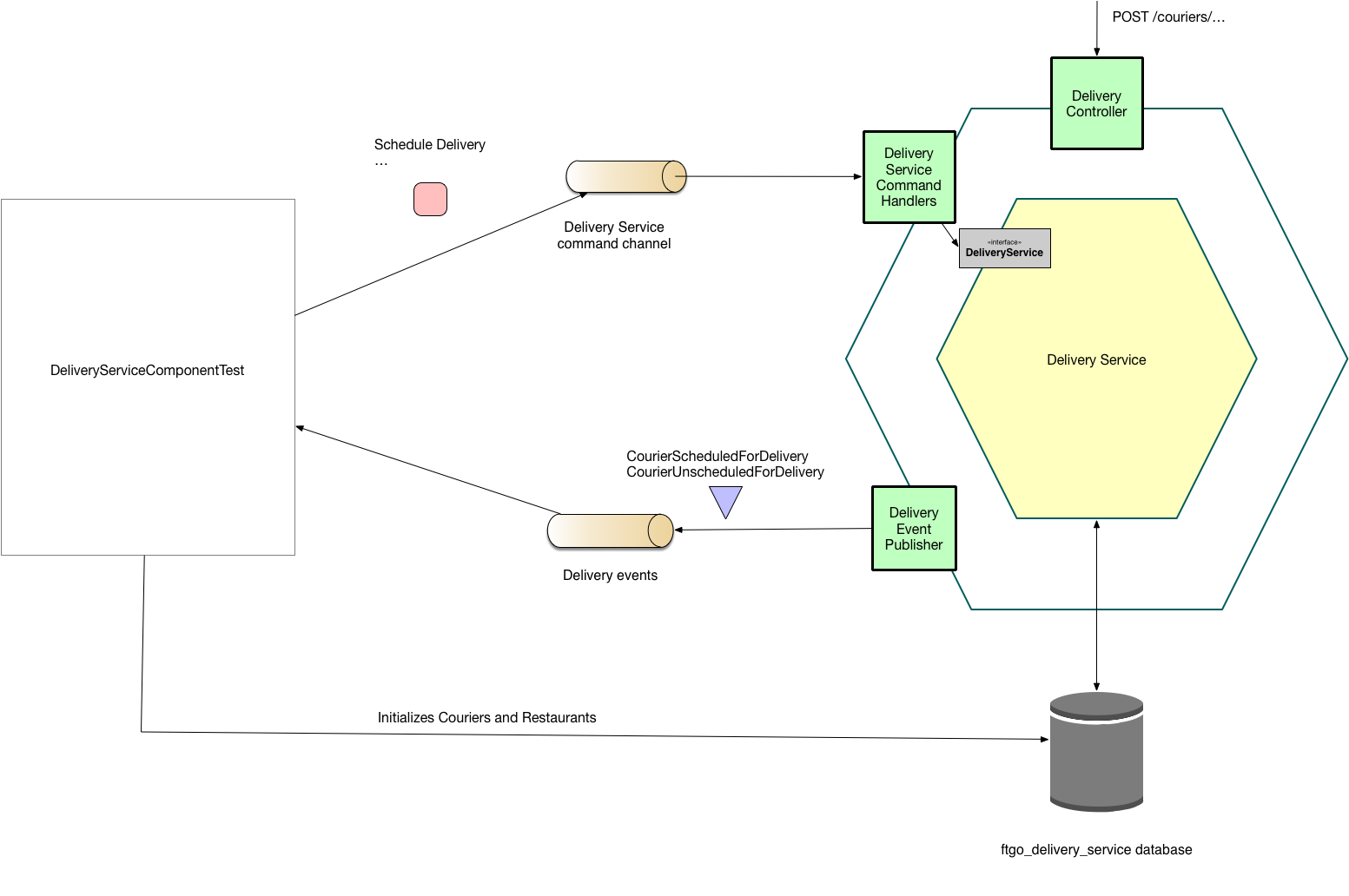
It sets up couriers and restaurants (normally replicated from the ftgo database via triggers) using JPA.
DeliveryServiceComponentTest then sends a command message to the Delivery Service and asserts that it publishes the expected events.
Deploying the Delivery Service
Like the FTGO application, the Delivery Service is a Spring Boot application that is deployed a Docker container.
The ftgo-delivery-service/Dockerfile file defines the container image.
The docker-compose.yml file defines at ftgo-delivery-service container along with the infrastructure services needed for transactional messaging: Apache Zookeeper, Apache Kafka, and Eventuate Tram CDC.
Git commits
These changes are in the extract-delivery-service-03-define-service branch and consist of the following commits:
- Renamed
ftgo-delivery-service*modules toftgo-delivery-backend* - Define the standalone service
Delivery Service - Replaced Service->Monolith triggers with Tram events
- Implemented Component Test for
Delivery Service
What’s next
- Look at the FTGO monolithic application code
- Read chapter 13 of my book Microservices patterns, which covers refactoring to microservices
- Read the next step, which uses the
Delivery Service. - Talk to me about my microservices consulting and training services